
Pod创建过程
- pod
- 2024-08-18
- 0评论
Pod创建过程
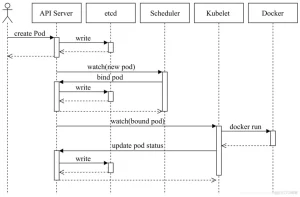
比如,要部署一个deployment,文件叫nginx.yaml
执行命令 kubectl apply -f nginx.yaml 命令, kubectl根据kubeconfig配置文件里面指定的api-server地址,将nginx.yaml传给api-server
API Server 接到nginx.yaml的内容请求后,开始分析里面的内容,校验内容的语法和格式是否正确,语法和格式正确之后,开始分析内容,发现要部署一个deployment,
然后告诉etcd,说我要部署一个deployment,你先帮我记录一下
api-server告诉Scheduler调度器,说我要部署一个deployment,镜像是nginx, 数量是1, 你帮我看一下,要部署到哪个node节点
然后开始进入调度环节,调度环节分为3个步骤,分别是:预选步骤,优选步骤,节点绑定
预选步骤:
比如不能部署的节点,master节点
节点上剩余的资源是否大于pod 请求的资源
pod是否指定了nodeName的名称,如果指定了nodeName,就直接进入节点绑定
pod是否指定了label标签
是否有亲和性Affinity与反亲和性AntiAffinity
是否有污点(taints)与容忍性(tolerations)
将所有得符合条件的node节点, 过滤出来,进入下一个步骤
优选步骤:
将过滤出来的 Node节点进行打分,会根据节点cpu数量、cpu使用率、内存、内存使用率、磁盘等多个条件,进行综合计算,分数从高到底,然后选择那个分数最高的节点,例如node1
调度器也会考虑一些整体的优化策略,比如把 Deployment 控制的多个 Pod 副本分布到不同的主机上
或者使用负载最低的主机等策略
节点绑定:
Scheduler调度器将分数最高的节点,例如node1,调度器告诉api-server,说请把pod调度到node1节点,
然后api-server告诉etcd,说我要将pod部署到node1节点,你帮我记录一下
api-server告诉node1节点的kubelet,说我要部署一个pod到node1节点,你帮我创建一下
在创建pod时,需要镜像nginx,查询node1节点是否有nginx的镜像,如果没有nignx镜像,就去拉取这个镜像
如果这个镜像是公共镜像,则不需要相关镜像仓库的认证,如果这个镜像是私有镜像,则需要认证参数imagePullSecret
当镜像拉取之后,开始创建pod,pod需要分配cpu、内存、存储volume、ip等
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。
那么,这个 CRI 请求,又该由谁来响应呢?如果你使用的容器项目是 Docker 的话,那么负责响应这个请求的就是一个叫作 docker-shim 的组件。它会把 CRI 请求里的内容拿出来,然后组装成 Docker API 请求发给 Docker Daemon。需要注意的是,在 Kubernetes 1.24版本之前,docker-shim 依然是 kubelet 代码的一部分,在1.24版本时,kubelet 删除了docker-shim的代码。
在k8s 1.24版本之前和之后,创建Pod的方式略有不同。
如果k8s版本低于1.24,创建过程如下:
- Kubelet 通过 CRI 接口(gRPC)调用docker-shim,请求创建一个容器。CRI 即容器运行时接口,这一步中,Kubelet 可以视作一个简单的CRI Client,而 docker-shim 就是接收请求的 Server。docker-shim是内嵌在 Kubelet 中的,所以接收调用就是 Kubelet 进程。
- docker-shim收到请求后,转化成 docker daemon的请求,发到docker daemon 上请求创建一个容器。
- Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程 containerd 中,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器。
- containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让 containerd-shim 去操作容器。是因为容器进程需要一个父进程来做诸如收集状态。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系)。
- 创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范,那就是 OCI。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器。
- runC 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。
K8S -> kubelet -> CRI -> docker-shim -> Dockerd -> Containerd -> containerd-shim -> runC
进程管理情况:Containerd(管理所有containerd-shim) -> Containerd-shim(管理单个容器) --> runC容器进程

如果k8s版本在1.24及其之后,创建过程如下:
- Kubelet 通过 CRI 接口(gRPC)调用CRI plugin。从 containerd 1.1 开始,社区选择在 containerd 中直接内建 CRI plugin,通过方法调用来进行交互,从而减少一层 gRPC 的开销。
- containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让 containerd-shim 去操作容器。是因为容器进程需要一个父进程来做诸如收集状态。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系)。
- 创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范,那就是 OCI。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器。
- runC 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。

K8S -> kubelet -> CRI -> (CRI plugin)Containerd-> containerd-shim -> runC
进程管理情况:Root-init(宿主机上1号进程)–> Containerd-shim(纳管单个容器) --> runC容器进程
当pod创建的时候,设置cpu、内存,通过resource参数设置request和limit,request是立即生效的参数,启动时候就要分配,limit是最大限制,不能超过,如果超过的话,会发生pod重启或者oom内存超出。
当创建pod需要ip的时候,CNI插件就应该工作了,常用的CNI插件有flannel和calico,比如该集群使用的是flannel。
flannel的网络模式有2种,vxlan模式和hostgw模式,常用的模式是vxlan模式,vxlan模式是将一个网段分配给一个node节点,node节点的pod绑定的ip都在这个网段内。
那这个网段内的ip是如何分配的呢,flannel其中的一个组件叫ipam,ipam全称叫 ip address manage (ip地址管理),是用来管理ip地址池的。
ipam记录哪些ip被使用了,哪些没有被使用,当申请ip地址的时候,ipam就将一个没有使用的ip分配给新创建的pod。
host-local是最常用的IPAM插件。它的工作方式如其名:-
分配范围:从所在Node的
podCIDR子网中分配IP。 -
管理机制:在宿主机本地管理IP分配状态,确保单个主机上IP地址的唯一性。它会将已分配的IP信息记录在本地文件系统中,默认路径是
/var/lib/cni/networks/<网络名>/。在该目录下,每个已分配的IP会对应一个文件,文件内容为使用该IP的容器ID。同时,它会记录最后一个被保留的IP(如/var/lib/cni/networks/last_reserved_ip.0),从而知晓分配位置。 -
分配算法:
host-local采用的分配策略是在给定的地址范围内进行轮询(round-robin)。其原理是每次分配时,会读取上次分配的IP记录(last_reserved_ip.0),然后尝试分配下一个可用的IP地址。
当新的ip分配的时候,会创建一个虚拟网卡对,叫 veth peer ,这个虚拟网卡对有2个端口,一端绑定在pod上,一端绑定在cni0网桥上
如下图所示:
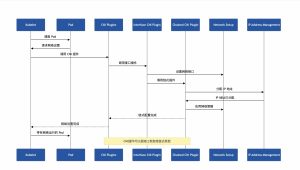
为了详细说明序列图中描述的每个步骤,涉及 Kubelet、Pod、CNI 插件(包括接口和链式 CNI 插件)、网络设置和 IP 地址管理(IPAM)之间的交互,让我们深入了解这个过程:
- 调度 Pod:Kubelet 安排一个 Pod 在节点上运行。这一步启动了 Kubernetes 集群中 Pod 的生命周期。
- 请求网络设置:Pod 向 Kubelet 发出网络设置请求。这个请求触发了为 Pod 配置网络的过程,确保它可以在 Kubernetes 集群内进行通信。
- 调用 CNI 插件:Kubelet 调用配置的容器网络接口(CNI)插件。CNI 定义了一个标准化的方式,用于容器管理系统在 Linux 容器中配置网络接口。Kubelet 将必要的信息传递给 CNI 插件,以启动网络设置。
- 调用接口插件:CNI 框架调用一个接口 CNI 插件,负责为 Pod 设置主要的网络接口。这个插件可能会创建一个新的网络命名空间、连接一对 veth 或执行其他操作,以确保 Pod 具有所需的网络接口。
- 设置网络接口:接口 CNI 插件为 Pod 配置网络接口。这个设置包括分配 IP 地址、设置路由和确保接口准备好通信。
- 调用链式插件:在设置网络接口之后,接口 CNI 插件或 CNI 框架调用链式 CNI 插件。这些插件执行额外的网络配置任务,比如设置 IP 伪装、配置入口/出口规则或应用网络策略。
- 分配 IP 地址:作为链式过程的一部分,链式 CNI 插件中的一个可能涉及 IP 地址管理(IPAM)。IPAM 插件负责为 Pod 分配一个 IP 地址,确保每个 Pod 在集群或命名空间内具有唯一的 IP。
- IP 地址已分配:IPAM 插件分配了一个 IP 地址,并将分配信息返回给调用插件。这些信息通常包括 IP 地址本身、子网掩码和可能的网关。
- 应用网络策略:链式 CNI 插件将任何指定的网络策略应用于 Pod 的网络接口。这些策略可以规定允许的入口和出口流量,确保根据集群的配置要求进行网络安全和隔离。
- 链式配置完成:一旦所有链式插件完成了它们的任务,Pod 的整体网络配置被认为已完成。CNI 框架或链中的最后一个插件向 Kubelet 发送信号,表明网络设置已完成。
- 网络设置完成:Kubelet 收到了 Pod 的网络设置完成的确认。此时,Pod 具有完全配置的网络接口,具有 IP 地址、路由规则和应用的网络策略。
- 带有网络运行的 Pod:Pod 现在已经运行,并配置了网络。它可以与 Kubernetes 集群中的其他 Pod 通信,根据网络策略访问外部资源,并执行其指定的功能。
当这些都准备好之后,pod就开始运行了,kubelet收集到pod运行的信息之后,会将这些信息返回给api-server。
api-server收到pod运行在node1节点成功之后,会将这些信息返回给etcd,最终etcd会记录这个deployment的信息。
大致过程如上所示。